
Agentic Narrative Game Engine
Lunar Command is pioneering the future of Agentic Gaming through our proprietary Graph-based Retrieval and Action Generation architecture. By anchoring the creative power of Generative AI to a deterministic Knowledge Graph, we’ve eliminated the 'hallucination loop' that plagues modern AI narratives. Our flagship RPG, Moon Base Theta, demonstrates a high-performance hybrid system that maintains 100% world-state consistency via a tech stack optimized for low-latency narrative orchestration.
Read The White Paper
↓
White PaperLunar Command: The GRAG Architecture
A White Paper on Hybrid Generative Narrative Systems
Published: February 6, 2026
Author: Chris Colinsky, Principal Engineer & Architect
Affiliation: Lunar Command
Subject: Text-Based RPG Engineering, Agentic RAG, and Graph-Based World State
1. Summary
The Lunar Command project represents a paradigm shift in interactive fiction and text-based role-playing games (RPGs). By moving away from the "hallucination-prone" nature of pure LLM-driven narratives, Lunar Command introduces the Graph-based Retrieval and Action Generation (GRAG) architecture.
This system bifurcates the gaming experience into two distinct layers: a Deterministic State Engine powered by a Gremlin-based Knowledge Graph, and a Generative Narrative Layer powered by open source Small Language Models (SLMs). The result is a high-fidelity, sci-fi/cosmic horror experience that maintains 100% world-state consistency while delivering the infinite prose variety of modern generative AI.
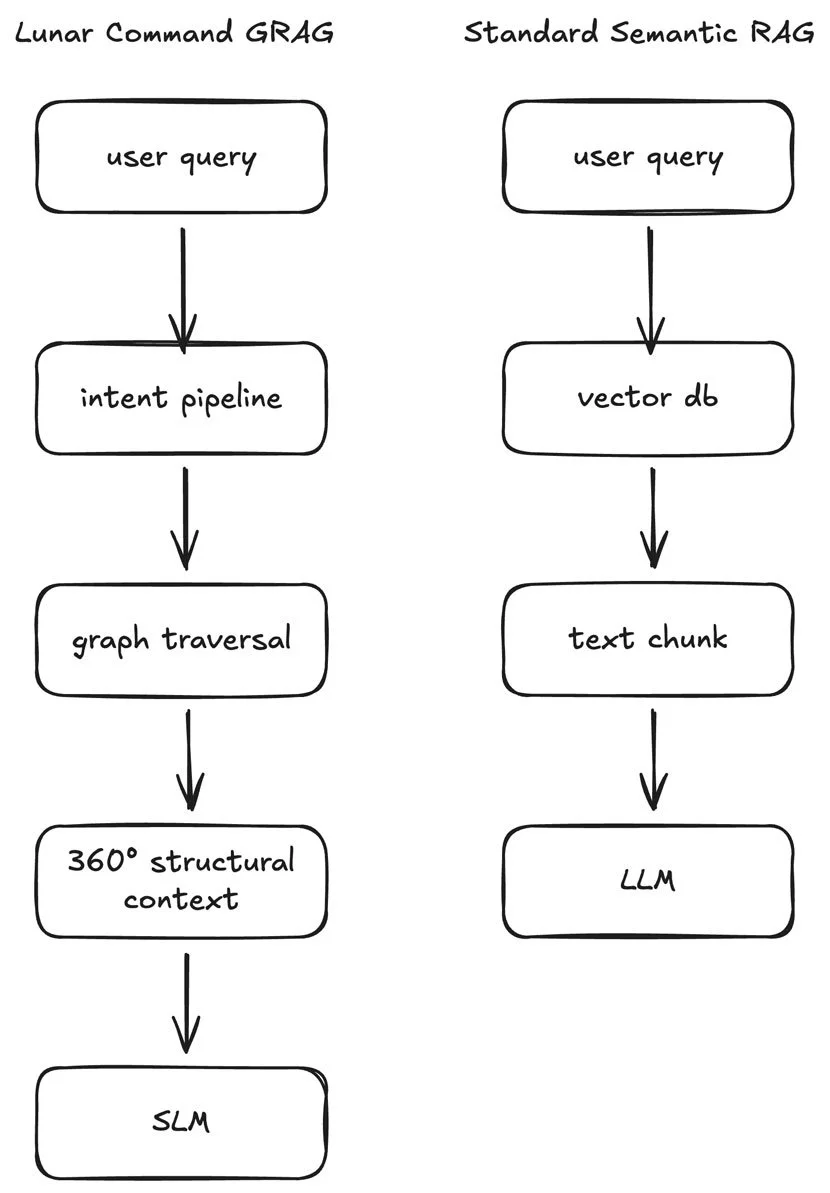
While standard RAG relies on fuzzy semantic similarity from a Vector DB, GRAG utilizes a multi-stage pipeline that resolves player intent into authoritative graph traversals. This ensures that the SLM is fed a "360-degree" structural snapshot of the game world-guaranteeing that every generated word is anchored in the deterministic truth of the underlying simulation.
2. Introduction: The Problem of "Ghost in the Machine"
Current generative AI games suffer from a fundamental flaw: the "hallucination loop." When an LLM is responsible for both the narrative and the game logic, the world becomes "mushy." Doors that were locked suddenly open; NPCs forget they were just talked to; and the physical laws of the game world shift based on the LLM’s next token prediction.
Lunar Command solves this by treating the LLM not as the "Game Master," but as a Textual Renderer. The "Game Master" is actually a deterministic pipeline of microservices that validate every player action against a rigorous mathematical model of the lunar base.
3. The World of Moon Base Theta
3.1 Setting and Lore
While the 1969 Apollo landings were celebrated globally, they masked the existence of the Lunar Xenoarchaeology Project (LXP). Operating from Moon Base Theta within the Schrödinger crater, elite personnel discovered extralunar artifacts emitting rhythmic resonance deep within the lunar lava tubes. In a catastrophic breach of protocol, attempts to harness these alien power sources triggered a massive energetic pulse, destroying the base and killing all personnel. To avoid public fallout and potential cosmic retaliation, the mission was scrubbed from classified records, leaving the site a silent tomb for over a century.
3.2 Gameplay Mechanics
Lunar Command utilizes a simplified D&D 5th Edition (5e) rule set and character sheets. Actions are resolved using a cryptographically secure dice roller (CSPRNG), ensuring that player stats and luck matter as much as their narrative choices.
4. Technical Architecture: The GRAG System
The game architecture is classified as a Graph-based Retrieval and Action Generation (GRAG) system. It is composed of four primary services orchestrated by a "Master Control Program" (Game Agent).
4.1 System Overview
The architecture follows a modular microservices pattern where a central Game Agent orchestrates the flow between specialized services for intent recognition, graph-based state management, and narrative generation. By decoupling deterministic game logic (Graph and D20 services) from probabilistic generative processes (LLM service), the system maintains a rigid "Source of Truth" while providing fluid, immersive storytelling. This entire pipeline is wrapped in a production-ready observability layer using Langfuse for agentic tracing and HyperDX for system-wide telemetry.
The architecture is engineered for cost-efficiency by offloading all computationally expensive logic-such as pathfinding, world-state validation, and dice mechanics-to deterministic microservices, ensuring the LLM is only invoked for high-value narrative rendering and intent fallback. By utilizing self-hosted open-source models like Mistral 24B, the system eliminates per-token usage fees and external API overhead, effectively turning inference into a fixed infrastructure cost. Furthermore, the use of a Graph Database enables highly targeted context injection, which drastically reduces prompt token counts compared to traditional RAG systems that often rely on large, redundant document chunks.
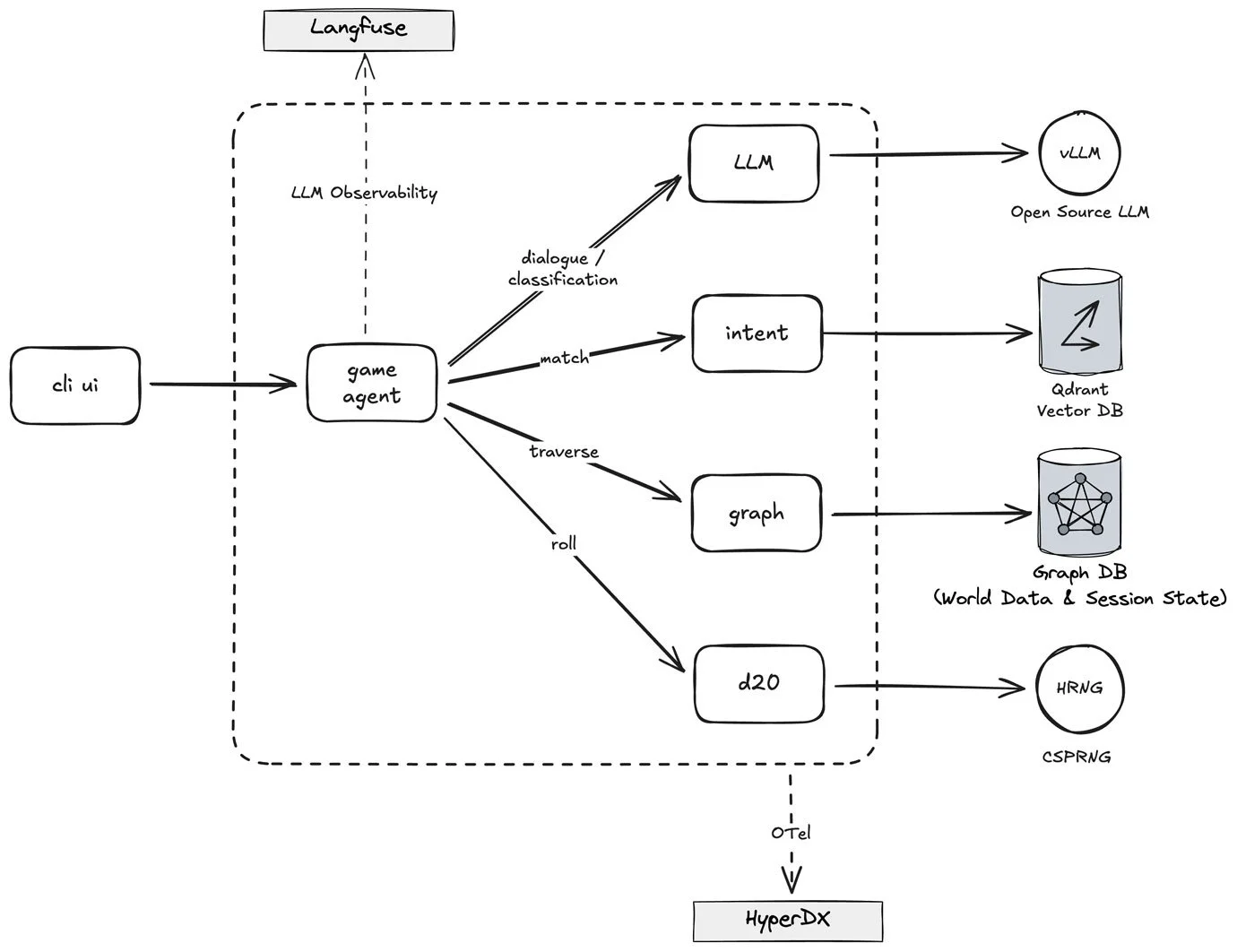
4.2 The Intent Pipeline (NLU)
When a player types "> examine the note on the console", the input enters the Intent Pipeline to identify the Action and Object pair - (examine, note).

- Preprocessing: The system performs NLP lemma extraction (identifying the root verb "find" and object "note").
- Metadata-Filtered Vector Search: Using Qdrant, the service compares the input against a vector database using a two-part strategy:
- Strict Search: Filters by
Action == Verbto prevent "Intent Drifting." - Broad Search: Uses the intent vector for semantic matching if strict search fails.
- Strict Search: Filters by
- Self-Healing LLM Fallback: If vector scores are below threshold, a Mistral 24B model is invoked. It is constrained by a CSV-based mapping of valid action/object pairs, effectively turning the LLM into a sophisticated classifier rather than a free-form generator.
4.3 The Graph Service (Authoritative State)
The heart of the system is a Gremlin/Tinkerpop graph database. Nodes represent Players, NPCs, Rooms, and Items; Edges represent relationships like LOCATED_AT or CONNECTS_TO. Every action is a graph traversal, ensuring structural consistency.
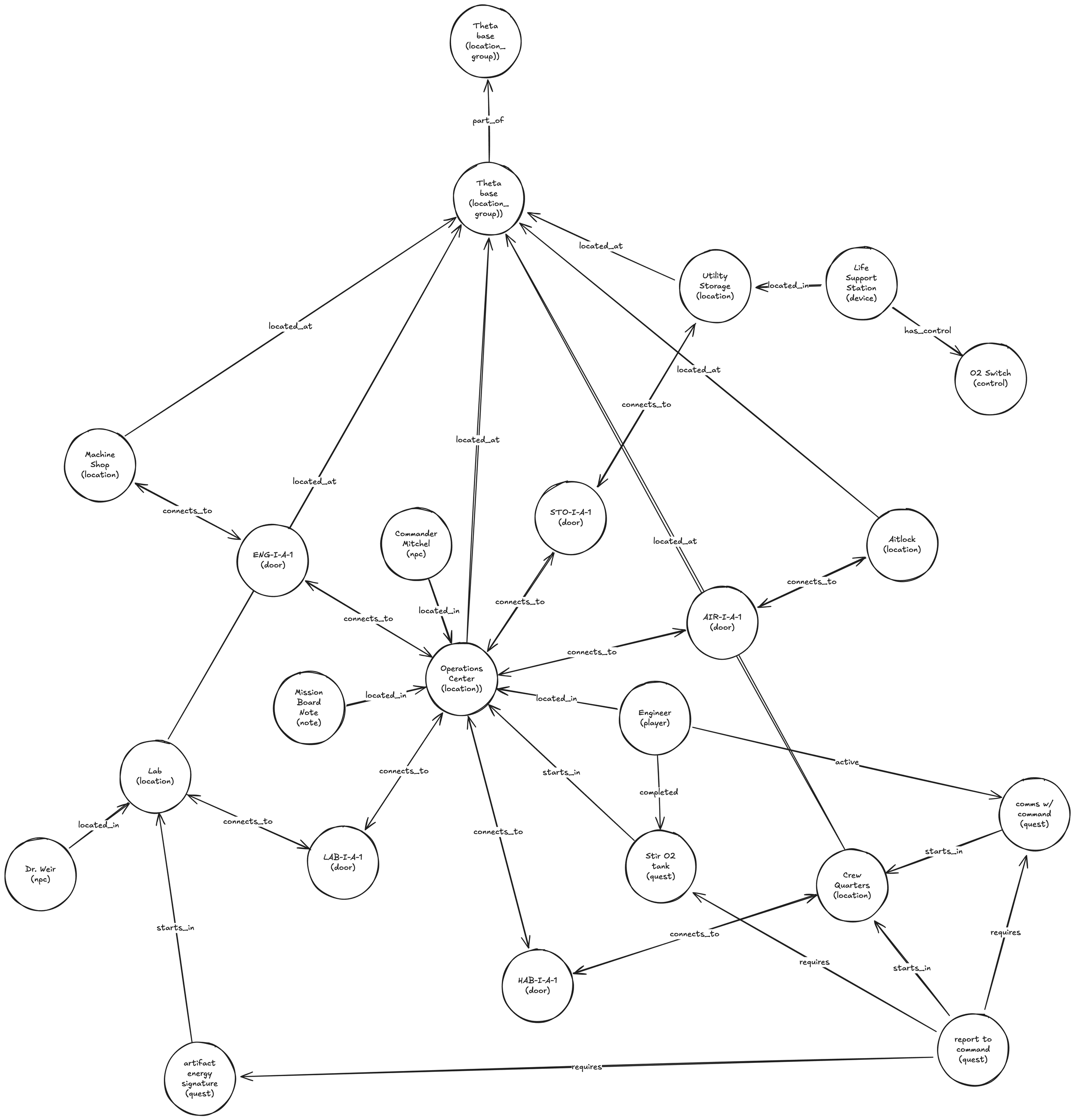
4.4 Generative Rendering
Once the Graph Service confirms an action, the Game Agent sends the "Resulting State" to the LLM. The AI is forbidden from changing the outcome; it only decides how that outcome is described.
5. Technical Deep Dive: Engineering for an Agentic World
5.1 Contextual Disambiguation
If a player says "Open the door," the game solves this using Agentic Contextual Reasoning: the Agent queries the Graph for all nearby interactive objects and provides the SLM with a list of IDs to choose from based on the user's conversation context. Data is serialized into Jinja2 templates that present a structured list of potential objects (including IDs, names, and labels) to the SLM for precise identification.
5.2 Deterministic Rule-Enforcement via Graph Traversal
In Lunar Command, "Rules" are not code; they are Edges. For example, a LOCATED_IN edge property dictates if an object is in a room or not. Tool execution (Move, Use, Talk) is validated against these graph properties before narrative generation occurs.
5.3 Dynamic NPC Conversations & Persistence
Lunar Command features a state-aware dialogue system that solves the "NPC amnesia" common in LLM games through a distributed data model and a multi-step orchestration pipeline:
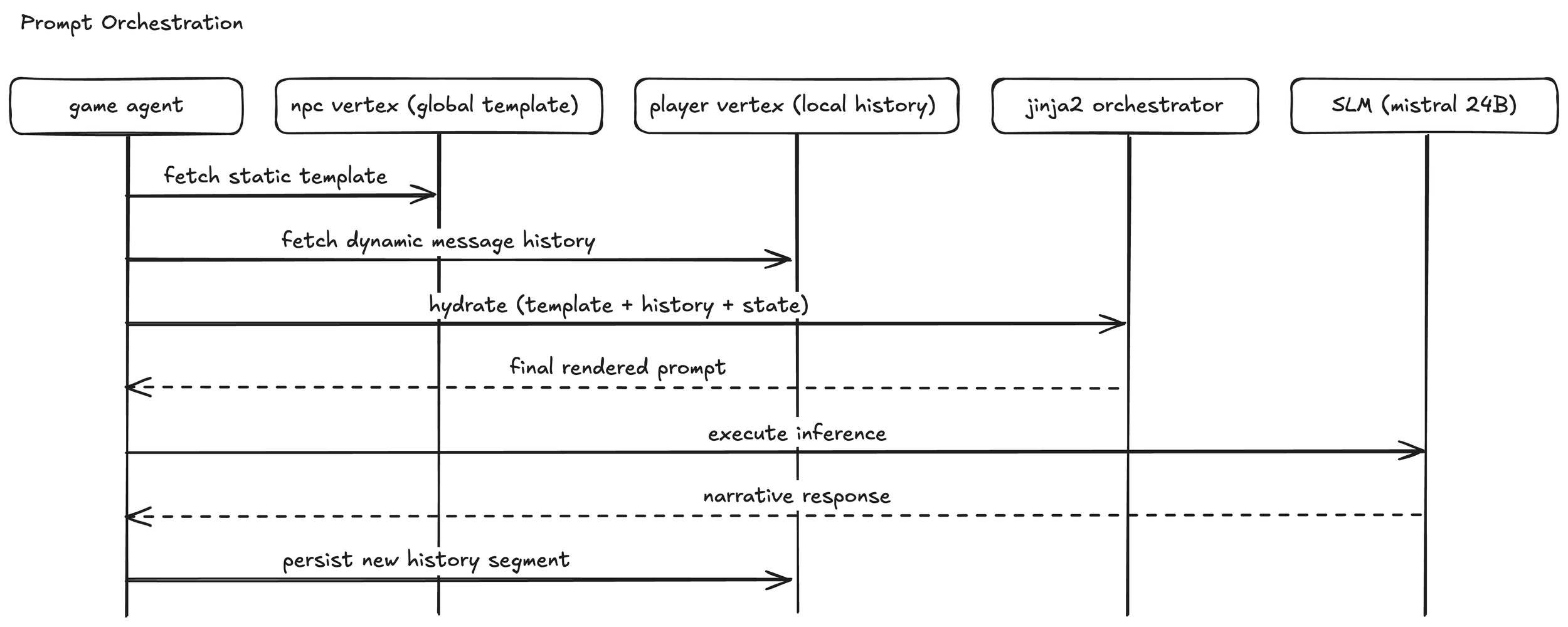
- Distributed State Model: Conversation templates are stored on the NPC vertex and are shared across all players, ensuring narrative consistency. Conversely, the individual conversation history-including the specific prompts and generated SLM responses-is persisted on the Player vertex. This separation allows the world to remain static while player interactions remain unique and persistent.
- Step-by-Step Orchestration: Conversations are scoped to specific NPC-Location pairs and consist of sequential "Steps." When a player initiates a dialogue, the Game Agent retrieves both the global template and the player's specific history. It identifies the current progress (Step index), reconstructs the full message history (system, user, and assistant roles), and applies the next template step to form the final prompt for the SLM.
- Contextual Reconstruction: By rebuilding the historical dialogue from stored variables and templates at every turn, the SLM maintains a perfect "long-term memory" of the session without requiring massive, persistent context windows.
5.4 The Observability & Traceability Stack
Lunar Command implements a production-ready observability stack using Langfuse for agentic tracing and OpenTelemetry (HyperDX) for monitoring latency and local inference performance.
5.5 Model Sovereignty: Local SLMs
Lunar Command avoids commercial APIs in favor of local inference, ensuring zero network latency and total control over deterministic sampling. The architecture is standardized on Mistral-Small-24B-Instruct-2501, a model that represents the "sweet spot" for high-performance agentic workflows on consumer-grade hardware.
As detailed in the Mistral Small 3 announcement, this 24B parameter model provides a significant leap in reasoning, multilingual support, and tool-calling precision compared to smaller 7B or 8B alternatives, while remaining lean enough to fit within the 24GB VRAM envelope of an NVIDIA RTX 4090. By utilizing 4-bit quantization (AWQ/Marlin), the system achieves inference speeds of 60-65 tokens per second, enabling near-instantaneous narrative rendering and intent classification without the recurring costs of centralized LLM providers.
6. Infrastructure: The AI Workstation
To support the GRAG architecture's demand for low-latency inference and future fine-tuning, the project utilizes a custom-built AI workstation designed for high-density GPU compute within a homelab environment. This hardware stack is engineered to handle the thermal and power requirements of modern LLMs while maintaining a consumer-grade footprint.
6.1 Split-Role GPU Strategy
The system employs a dual-GPU configuration that separates production inference from development cycles. This "split-role" approach ensures that the narrative engine remains responsive even during model optimization phases:
- Primary Inference (RTX 4090): Dedicated to the vLLM inference server. By utilizing
awq_marlinkernels and strict VRAM management (limiting context to 16k tokens), the card maintains high-throughput generation for the active game state. - Training & Fine-Tuning (RTX 3090 Ti): Leveraged for fine-tuning the Intent Pipeline and narrative style. This secondary card provides an additional 24GB of VRAM, which can be pooled with the primary GPU for larger training jobs using distributed frameworks like Accelerate.
6.2 System Optimization
The infrastructure is tuned for maximum PCIe throughput and addressing of large VRAM pools. Key optimizations include:
- Kernel Tuning: Implementation of the AWQ-Marlin quantization kernel, which provides a 10x throughput increase over standard AWQ on Ada Lovelace architecture (RTX 40-series).
- Deterministic Pinning: The inference service is pinned to specific hardware IDs and isolated from system display tasks to prevent VRAM fragmentation and ensure consistent latency.
- Power Management: Strict power-limit protocols (capping cards at 350W) are applied during training modes to manage transient power spikes and thermal saturation.
7. Future Roadmap: From Beta to Artemis
The current Beta focuses on the Apollo Era (the past), proving the infrastructure's scalability. The full release will transition to the Future Era, set in a thriving international lunar base at the south pole. To support this transition, the following engineering milestones are prioritized:
7.1 Historical Authenticity via Fine-Tuning
To elevate narrative verisimilitude, the generative layer will undergo domain-specific fine-tuning on historical NASA datasets. By ingesting Apollo-era mission transcripts, flight journals, and technical hardware manuals, the model will be optimized to produce dialogue and technical descriptions that reflect the precise lexicon and procedural atmosphere of 20th-century space exploration.
7.2 AI-Augmented World Building & Internal Tooling
Content creation will move toward a "Human-in-the-Loop" orchestration model via custom internal tools. A visual graph editor will allow designers to architect the world's structural topology, while integrated LLM-interactive sessions will assist in generating rich narrative metadata-such as location descriptions and quest templates-directly into the graph nodes during the design phase.
7.3 Architectural Scaling: Property Decoupling
To maintain sub-millisecond graph traversal speeds as the world expands, vertex and edge property data will be decoupled from the core graph engine. Structural relationships will remain within the Gremlin graph, while heavy metadata and transient state properties will migrate to a document-oriented NoSQL solution (e.g., MongoDB), ensuring the graph remains "skinny" and performant.
7.4 Robust Persistence & Graph Storage
The system will transition from an in-memory graph (currently managed via containerized disk-snapshots) to a production-grade persistent storage layer. This roadmap includes migrating to a dedicated Gremlin-compatible persistence engine or a managed solution like AWS Neptune, providing the ACID-compliant foundation necessary for a persistent, multi-user lunar simulation.
7.5 Automated Evaluation & Narrative Faithfulness
To move beyond manual playtesting, the project is implementing a Hybrid Evaluation Harness. By integrating RAGAS to verify factual anchoring against the graph and the RoleLLM framework to measure stylistic character adherence, the system programmatically ensures both narrative truth and role-playing integrity. This harness, integrated into a Promptfoo regression suite, allows for rigorous testing of the "GRAG Triad" (Faithfulness, Relevancy, and Contextual Precision) alongside character-specific benchmarks as the world-data expands.
8. Conclusion
Lunar Command proves that the future of AI in gaming isn't "more AI," but "smarter integration." By anchoring a generative model to a deterministic graph-based world state, we have created a system where curiosity is rewarded, choices are permanent, and the world is as solid as the lunar regolith.
Appendix A: Narrative Proof of Concept
The following character and quest structures serve as the primary implementation testbed for the GRAG architecture, demonstrating how deterministic state and generative prose coexist within the Moon Base Theta and Lunar Xenoarchaeology Project (LXP) setting.
A.1 Character Roster & State Roles
The characters at Moon Base Theta are not merely dialogue trees; they are active agents whose "Trust" and "Knowledge" states are tracked as vertex properties within the graph.
- Chief Engineer Robert Gallagher (Player Character): A veteran technician whose expertise in life support and mechanical systems serves as the player's primary interface with the base's deterministic microservices.
- Commander Jack Mitchell: The mission lead. Mitchell represents the "Command Authority" gate; his interactions are governed by a rigid adherence to protocol, serving as a friction point for the player’s agency.
- Dr. Alistair Weir (Scientist/Medical): The narrative catalyst. Weir’s state-transitions from "Scientific Observation" to "Obsessive Genius" drive the progression of the cosmic horror arc.
- Gabriel Caul (Comms/Ops): The informational gatekeeper. Caul manages the flow of data between the base and Earth, acting as the primary enforcer of the mission's underlying conspiracy.
A.2 Beta Quest Architecture
The Beta quest-line is designed to stress-test the interaction between the Intent Pipeline and the Graph Service:
- System Maintenance (Operational Baseline): Players perform routine engineering tasks (e.g., life-support cycling). This validates the "Action Generation" phase, where player intent is mapped to deterministic mechanical outcomes.
- Internal Investigation (Relational Discovery): A shift toward clandestine objectives forces the system to utilize "Stealth Completion" logic and metadata-filtered searches to handle player-driven inquiry into crew loyalties.
- Anomalous Identification (Xenotechnology): Scientific analysis tasks test the system's ability to handle new "Knowledge" states, where the LLM must render descriptions of alien artifacts based on retrieved sensor data.
- Operational Reporting (The Conclusion): The final sequence requires the player to navigate the conflicting instructions of the Commander and the Communications Specialist, demonstrating the architecture's capacity for complex, multi-NPC state management.
A.3 Environmental Fidelity & Narrative Noise
To enhance immersion, the environment is populated with "non-essential" interactive objects-technical manuals, maintenance logs, gear and personal mementos. These objects provide a high volume of "Narrative Noise," requiring the LLM to maintain consistent stylistic rendering while the player filters through redundant data to identify critical mission-relevant information.
Contact
Interested in learning more? Fill out some info and we will make contact.